

In recent years, there have been major changes, and through new neural architectures of machine learning, we have known great advances, especially in natural language processing and machine translation. Now that we are in full techno-social transformation, the digital transformation of the media into Euskera and the integral development of Euskera come together.
Artificial intelligence and natural language processing: from symbolic strategy to machine learning
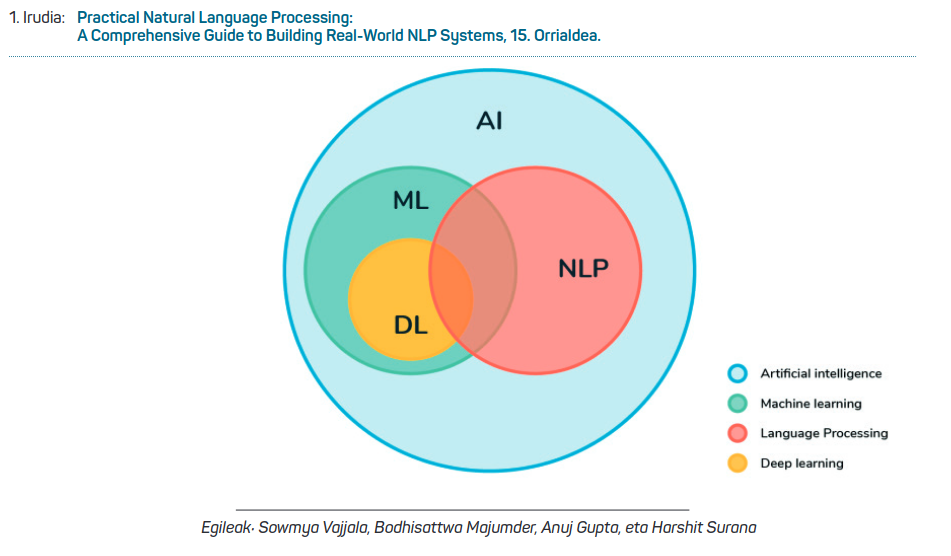
Despite the difficulty and courage to provide a precise definition of artificial intelligence, it can be said that the discipline that generates the ability to imitate and learn people"s mental processes through computer systems is the ability of machines to imitate human intelligence.
So, if artificial intelligence is the ability of machines to mimic the human mind, and understanding and language are the most obvious manifestations of human intelligence, Natural Language Processing (hereinafter NLP) is a discipline that lies at the center of artificial intelligence. For example, the NLP is known as the AI-complete problem in the scientific and technological field of artificial intelligence, that is, it is an artificial intelligence field in which complex and robust algorithms are built.
According to a report by the HITZ Center of the UPV/EHU, 40% of Artificial Intelligence research production is related to PDI, which can provide us with the measurement of the evolution and development of artificial intelligence in language in recent years. The PDRS is in charge of researching computational tools to facilitate, through language, communication between people and machines, even among people. Activity therefore becomes a key element, and more in the future.
In recent years, artificial intelligence has experienced remarkable advances in language, especially through algorithms based on deep neural networks, known as Deep Learning. The improvement of these algorithms has made it possible to automate many services, obtain excellent results in different tasks and in many languages, and, as we know, excellent results have also been obtained with the Basque Country.
Until now, artificial intelligence and, in particular, the processing of natural language have dominated two strategies and scientific approaches; on the one hand, a paradigm based on symbolic approximation; and on the other, an approach based on machine learning that has gained strength since 2010 and has become the leader.
According to the symbolic approximation, we wanted to describe the language with understandable rules for machines, teaching the machine the details of all the levels and characteristics of the language: lexical, morphology, morphosyntax, syntax, semantic, pragmatic. Computational linguistics has gained special importance in this approach, since it has sought the rigor and systematization of the description of the language in collaboration with linguists and informatics, but often low coverage systems and technologies have been created. The symbolic approach has traditionally been dominated in the main tasks of the NLP, as well as in machine translation. In the case of automatic translation, good results have been obtained for exercises between languages of high similarity and grammatical structure (as demonstrated by the automatic free code system based on Apertium 3 rules). Conversely, the systems developed by Matxin translators 4 based on free code (developed by Elhuyar and the IXA Group of the UPV/EHU) or by Lucy Software for the Basque Government were far from the results of systems such as Apertium. That is, the automatic translators between Spanish and Catalan or Galician worked well, but between Spanish and Basque did not.
The strategy is now based on machine learning and deep learning. The machine learns what it shows with examples in machine learning (Corpus textual large and bilingual) and then applies them in similar cases. In deep learning, in addition to the above, the machine can also learn what derives from the exposed: deep learning to achieve this behavior uses architectures based on neural networks.
Mastery of systems learning from examples through machine learning and in particular through deep learning techniques has dramatically increased the quality, maturity and accessibility of profile technologies. It can be said that the instruments so far had a low maturity level, while the current ones are capable of being integrated into many production processes.
The research carried out over the years and the presence of trained top-level researchers, the explosion on the Internet has led to large masses of text and data collections (with many examples of machine learning), the great computing ability to train neural networks and the major technological corporations are making a great economic and human effort to get better results in tasks such as machine translation. All of this has been a radical change and an outbreak that opens up opportunities that until now we have not even imagined. This approach has been a revolution in Basque language technologies.
In addition, in the last three years, a new change in the composition of NLP is developing that is absolutely disruptive: general neural linguistic models (oriented to broad domains) are trained, then, through small workouts, when we are able to function perfectly in tasks of another domain or another language.
Giant tech corporations (Google 6, Facebook 7, Amazon, etc.) transfer learning techniques are being used for the development of NLP applications. For example, Google recently modified the basic search engine algorithm with an algorithm based on previously trained neural profile models.
This paradigm shift represents great opportunities for the development of Euskera and minority languages, as transfer learning techniques allow a transfer of knowledge between resource-rich languages (examples, texts, data) and minority languages. This allows systems to learn using resource-rich language data to develop applications in other languages with fewer resources. To adequately respond to this disruptive paradigm, in 2020 we launched the DeepText project between Elhuyar, the HITZ Center and the Vicomtech research centers. 8.-
The results obtained with this technique have been very satisfactory and allow the construction of excellent applications for languages with little training data. (Agerri, San Vicente, Campos, Barrena, Saralegi and Agirre, 2020).
Improving machine translation: from symbolic approach to machine learning
The market and the use of automatic translation provide for a high rate of utilisation of forecasts made by firms such as Gartner9 and makes sense. The density of this growth, whose main growth factor is the growth of international global markets, accelerated by the acceleration of the process of digitalization - teleworking and digital communication - and -COVID-19.
But the explosion of neural machine translation has also contributed to this exponential rise. Machine learning and deep learning algorithms have greatly improved the level of quality in machine translation, and it can be said that it has accelerated ongoing processes with signs of disruption in sectors such as media and audiovisual. After the latest advances in Transformer systems (Vaswani et al. 2017) is based on neural architectures, based on neural networks, which has become the new art situation in neural machine translation and which has made a spectacular leap in the quality of technology.
The qualitative leap that has taken place in machine translation is, for example, the neural automatic translation of Elhuyar"s Elia. eus10, widely disseminated and used commercially in many companies and institutions. For example, between 2020 and 2021 Elia, Elhuyar’s automatic translator, has increased its number of users by 40%, has exceeded two million visits this year and translated over 610 million words. The translation of Spanish to Basque is the most widely used, but Elía performs translations between six languages: Basque, Spanish, French, English, Catalan and Galician.
As you know, it is not the only neural automatic translator on the market. Vicomtech has its own translator and is the engine used by the Basque Government Translation Service. 11.- PROPOSAL
In recent years, several Elhuyar research projects have been launched with the aim of achieving the highest level of quality and adequacy of our systems. Sometimes, fundamental research, 12, and applied research projects, on our own, make us have more and more automatic translators for the Basque country. We will have more personalized, implantable automatic translators with less cost and without social bias, and more pairs of profiles.
Personalization of the automatic translator
Personalised translations are increasingly needed in the machine translation market to respond more accurately to the specific requirements of content and users. Despite a significant improvement in gratuity levels, these improvements are significantly lower in specific contexts. In this respect, the engines of custom automatic translations can bring many benefits to any generic automatic translation.
What is most important is improving the accuracy of the translation, which in turn will reduce the cost of it (less investment in the post-edition period and in the human review). Another of the main advantages of Personalized Machine Translation is the Possibility of Memory Control and Use of Preferred Terminology.
Custom machine translation can be adapted to a particular use of syntax, terminology or style. In addition to improving the Accuracy of Translation Memories, a Custom Memory Service can facilitate the integration of the Memory model or the semi-automatic update of the Model to a media medium. This provides great customer autonomy to improve system customization.
In recent years, therefore, the main lines of research we have in place to improve neural automatic translators are:
-
-
- Possibility of using custom terminology in automatic translation models, without the need to create new models for each new terminological profile. Adaptation of terminology. The application of the terminology to translations is optional and dynamic, i.e. the possibility for the customer to choose to use a particular terminology at the time of translation and that the terminological dictionaries or glossaries he uses are absolutely dynamic and easy to update.
- Adequacy of models to the domain, registration and own style: Possibility to pre-process the client"s corpus or texts using different automatic filters. Adaptation of the model to the domain, registration and its own style through fine-tuning techniques. Later edition and retraining that allows a dynamic and incremental adaptation process.
-
Creating systems with less computing need
The idea is to create on-premise13 models and create portable machine translation systems based on Dockers semi-automatically. Light machine translation systems may be installed on computers or limited computer servers. This opens up great possibilities, as with fewer costs and resources, excellent and personalized automated translators trained with neural networks will be available to many organizations, better managing privacy and control demand.
Create systems that prevent any social and gender bias
As has been mentioned, neural architectures learn from the examples and textual corpus previously created, that is, from the data present in translations, texts and linguistic data. If there are (and exist) biases in these data, the neural automatic translator will reproduce these biases and give greater virality because their use grows exponentially.
Thus, in the automatic neuronal translation of the Basque language into Spanish, research has already begun to avoid and correct the bias of the Basque language to Spanish, balancing the body of training or balancing the model with a balanced corpus. (Saralegi, 2021).
New lines of future research
As we have mentioned, the emergence of the neural model has marked a spectacular advance in machine translation. However, existing systems require a large amount of data (deep monitoring) and normally require millions of sentences as parallel corpus. But surprisingly, human beings don"t need that condition to acquire language and to translate.
The goal of Mikel Artetxe (Artetxe, 2020) has been to completely remove this parallel data dependency to create unsupervised machine translation systems that require only a monolingual corpus. Unsupervised translation can open many paths to languages with little training data and it can be said that we are facing an important line of future research thanks to researchers like Mikel Artetxe (Facebook is now in the AI research group).
Our intentions are clear: we want to build better automatic neural translators linking Euskera with other languages, without bias, personalized and with lower computing costs, that is, personalized, viable and ethical high quality neural automatic translators.
Multilingualism, digital transformation and news consumption in a recent accelerated context: nearby scenarios.
Media consumption is increasingly coming through social and mobile networks; we are increasingly consuming media content without entering the media website. Local media are, for example, the most visited via Facebook and 66% of visits to Goierriko Hitza are received via Facebook (Mimenza, 2017).
Therefore, since Facebook offers the possibility of translating content through the automatic translation service, it is and will be better (not just Facebook), users receive their content translated by the media, either voluntarily or involuntarily. The calls and complaints that reach the media in Basque are not few because they understand that the contents of the media have errors in Spanish. (Rojas, 2020).
This means that the great content that is already out of control of the media is being received in other languages by users in Euskera, either via Facebook, Twitter or different additional machine translation systems that are inserted into our browsers. Soon and without realizing it, without knowing in what language the original text is, we will be able to read the news and the contents and it may be earlier than expected (Rojas, 2020). And the scenario can also come to turn language into a simple interface and a simple digital product (Apodaka, 2021).
In addition, as already mentioned at the beginning of the article, the real hypothesis is to assume that better memory systems will be available, even among the unforeseen languages. Big tech corporations like Facebook, Twitter Inc. and Alphabet are working hard on it. To this we must add that the weight of social networks in the consumption habits of young people and future users is even greater (Arana, Amezaga, Egia et el 2021), so the trend will be consolidated.
We have commented that there is more and more digital content, and although in the pandemic there has been an increase in Basque digital media, the Spanish media have grown more 14. The work carried out must not be underestimated, but some trends will be accelerated and the proportion of our content in Basque will decrease if we do not start working on other paths. The increase in digital content, the massive use of digital communications, the use of social networks and the improvement of artificial intelligence will only increase the difference. Neural machine translation should play a fundamental role in translating the digital mass content generated into our language.
Likewise, it is not an unreal strategic hypothesis that the media located in the Basque Country and focused in Spanish will increase the offer of contents in Basque. Naiz .eus offers more and more content in Basque and is immersed in an applied research project for the incorporation of machine translation, and the same could be said of the media of Grupo Noticias o Correo (Vocento). The newspaper El País, with editions adapted to Brazil or Catalonia, has long used the automatic translation edited by publications such as El Periodico de Catalunya, La Vanguardia, the BBC or La Voz de Galicia.
If they began to offer Spanish-language media in Basque that give a major importance to local news, it would be an important competition for the media that have had the hegemony of local news in Basque and the ecosystem. The impact it would have on readers and subscriptions would be obvious, but there would be a risk of weakening the essentiality. In view of the qualities of neural machine translation, the facilities for integration of having in the media systems and the trends that have occurred in countries such as Catalonia, the real hypothesis is that this will occur before time and that the media in Basque should take very much into account. In addition, the Spanish media have important subsidies to translate the news to the Basque country, and if the award criteria reward the translated quantity, which represented an important economic incentive, it can be even more decisive in the size of the jump and the speed of its issuance.
Therefore, in summary, I foresee a series of strategic hypotheses in view of the threats that external variables may pose:
- That through the major technological corporations and the main social networks will begin to offer content in Basque in the high-quality Castilian languages.
- Erdal media will use machine translation to offer its contents in Basque and offer more products in Basque, especially news and local content.
- The consumption habits of young people and multilingual linguistic competence can make media adherence in Basque lose.
- Most of the information is produced in the other languages and only a narrow channel arrives in the Basque language.
Faced with this changing, rapid and complex context, new opportunities and areas are also opening up. Without a doubt, machine translation and the ease of creating multilingual content can open new paths, new opportunities and areas, explored yes (recalls the English version of Euskaldunon Egunkaria), but which have so far been impossible due to lack of resources.
The dissemination of contents in Basque in Spanish, French or English can mean an increase in the number of users, viewers and readers, as well as an increase in the visibility of contents in Basque. In fact, if a means of communication directed exclusively to Vasco-speakers began to disseminate content in large languages, one could reach readers who do not understand the Basque language, there would be content in Basque which would be found in the last places in the ranking of the Google search engine and the Basque citizens who do not completely dominate the Basque language could more comfortably assimilate the content.
In addition, opportunities are opened to offer products or services differentiated from the media content, for example by extending content in another language with a different brand or offering thematic portals in other languages. For example, creating a Catalan portal focused on Basque politics or disseminating the global contents of the Elhuyar Journal in English and competing with digital publications of scientific dissemination of great prestige.
On the other hand, when we are able to create excellent automatic translators between minority languages or to extend ourselves to other large languages, many minority languages will be able to use our content by taking great steps in its development process and building bridges with other languages now distant.
Finally, just as we are able to disseminate our content, we will be able to provide it from other languages and, therefore, we will be able to reach agreements with the Catalan, Spanish or English media, extending and enriching the offer of our media. We are aware that it is not enough with mere translation, it requires localization and content mediation, but we have a great opportunity to reach content that we would not have come with our resources and journalists in Basque.
It will be of great help if the media in Basque have at their disposal research centres leading in machine translation or technological agents such as Elhuyar are part of an initiative.
In addition, the media created in Euskera, deeply rooted and whose mission and function is closely related and indissoluble to the development of the Basque Country, is concerned about the possibility of expanding the offer in other languages besides the Basque Country. Although reflections and reflections are essential, this may imply a delay in decision-making that requires digital transformation and the speed of digitalization, which are taken by external rather than voluntary factors. I have dared to propose concrete suggestions and possible solutions to any concerns or fears that may exist.

From the media entirely in Basque to multilingual projects focused on Basque
Maintaining the hegemonic space in Basque and maintaining the essence of these media, a possible video page that we can draw can be transferred to multilingual and multimedia communication projects that offer multilingual content. By this I do not mean that we have to go to a symmetrical multilingual linguistic offer, but I think it is a strategic bet to make the Basque language a means of communication that offers multilingual content.
Seeking a virtuous balance, on the one hand, as a response to the potentiation and expansion of the spaces in Euskera necessary for the community and the communicative ecosystem of the Basque Country, and on the other, through our technological capabilities and potentialities (Leturia, 2021), giving place to digital transformation, the massive use of social networks and the predominant consumption of audiovisual in this Spanish ecosystem.
That is, we use automatic translation in the face of the exponential increase in digital content, automatic subtitling systems and personalized speech synthesis (and their combinations) to expand the Basque tube and translate more communicative content to the Basque; and on the other hand, we use the advances in the processing of natural language and the technologies mentioned so that the supply of these media in Basque has a greater presence in this sea of digital content. I believe that it is not an opportunity to offer content in Basque in other languages, because the technological platforms and the most used social networks are already being done, therefore, under a strategy, but it must be done because the great technological corporations are already offering this service.
I do not believe, therefore, that it is time to talk about choice, but that it is time to determine the nature of choice and how we are going to carry it out.
Working hypothesis (I): Offer all media content in multiple languages through machine translation.
The portal of Elhuyar Zientzia .eus has launched this path and in the following pages you can reflect on this option and see the first evaluation of what it has given so far. An option proposed is to automatically translate all contents of the medium or publication, provided that the automatic translation offers an adequate quality and in function of the objective readers that each media considers objective. Zientzia .eus can now be read in full in 5 other languages (Spanish, French, Catalan, Galician and English) and the Consumer magazine of the Eroski Foundation has opted to automatically translate all its content to the Basque language in the opposite direction.
With this route, my hypothesis is that it will increase the number of times it occurs, that the contents of the medium will be more accessible in the search engines and that it will increase the visibility of the contents in Basque. Subsequently, each media may decide to correct, monitor, or maintain them depending on the available resources and strategies. This new initiative may entail an increase in the number of visitors from outside the Basque Country, a rapprochement of users who do not dominate the Basque Country and an increase in the visibility of the Basque media on the Internet.
News recently interview Itziar Ituño and English translation of an Iranian person. It could happen that Berria translated the interview and put it on the website, and seeing the prestige of Itziar Ituño would involve many visits and increase the visibility of the Basque.
It has been said that translating into other languages would mean appearing in the news search engines in Spanish or English on the content of Euskera, while I do not think it is a very strong argument. On the one hand, because whoever searches for it in Spanish or in English will never find content in Basque in search engines; on the other hand, because if he finds it in another language, it would be good news because otherwise he would never find it; and, finally, because the configuration of the website or the mobile configured in Basque can force direct access to an Basque content by jumping from the content to the website.
In this sense, there are two important keys for this option to maintain the domain of content in Basque, on the one hand, that users have the browser and mobile in Basque, and on the other, that the website of the media be properly configured to access the content in Basque from an indexed content in Spanish (if we want the first option to be in Basque).
It is possible, therefore, to set in motion a multilingual communication medium that focuses technically on the Basque language, maintaining the balance between the potentiality of multilingualism and the hegemony of the Basque language.
Working hypothesis (II): Offer all media content in multiple languages asymmetrically through machine translation.
Despite the above clarifications, a media outlet can decide functionally to provide greater added value to the Basque offer. The idea would be that the contents in Basque were also taught in other languages, but functionally giving the Basque a higher priority and a hegemonic area. The broadcast of news in Basque of the automatic summary in Spanish, but offering a summary and not a complete report. Enrichment of Basque content (With the extraction of keys, visualization options, additional and rich content…)
Working hypothesis (III): Provide the media with differentiated and adapted communication products or offers in other languages.
For example, Berriak can create a specialized portal with news related to Basque politics in Catalan and English, or Elhuyar edits Zientzia magazine in English online. It could be done within the own brand (like the BBC or the newspaper El País) or under a differentiated brand depending on the marketing strategy (like the Erdal media do with the Basque: Gaur8, Ortzadar, Zabalik…).
This strategy can make it possible to differentiate from what is a means of trunk communication and function as an autonomous business line in terms of the hegemonic space of the Basque Country, but if a strong branch comes out the trunk will be able to take advantage of its strength with more entrances, more muscles and better commercial positioning.
Working hypothesis (IV): Sub-writing and massive dubbing of audiovisual media in Basque.
I believe that it can be an important decision to increase the visibility and accessibility of content in Basque, that all audiovisual produced in Basque is subtitled to other languages. That is, use transcription technology and machine translation consecutively or incorporate the translation and speech synthesis to generate automatic dubbing in the cases of subtitles.
Thus, the productions produced in Euskera, giving priority to Euskera, could be incorporated into other languages depending on the community or country to which it aspires. And of course, the reverse road: underwriting attractive and interesting periodic audiovisual pieces in Basque. If we add to this a personalized synthesis of speech (imitating the original speaker or through the voices created by ourselves), we can bring many communication products to the Basque Country by expanding, expanding and enriching our media offer.
Working hypothesis (V): Generate new communication projects in collaboration with international networks.
Using content in Basque and putting it in other languages, we can give them a new route, especially for minority languages. They can take advantage of universal content in Basque to help build an autonomous communicative framework in the recovery of their linguistic community. I am thinking of occitan, Welsh, Breton and European minority languages, at least in a first step.
In summary
In recent years, there have been major changes, and through new neural architectures of machine learning, we"ve known great advances, especially in natural language processing and machine translation. The paradigm of the new neural linguistic models has further improved the results, as we are able to generate high quality tools and applications with lower cost to certain domains and between different languages.
In a context of renewal and culmination of the technosocial transformation (change of consumption habits, predominance of digital content, acceleration of the process of digitalization carried out by the pandemic), the question of the digital transformation of the media into Euskera and the integral development of Euskera arises jointly. However, it is up to us to adopt independent strategies and make decisions, otherwise they will replace us with algorithms designed by technological corporations.
I have raised some working hypotheses and there may be others, but public policies promoting the transformation of the media into Basque need a new impulse. Considering that the work of the media in Euskera is the creation of hegemonic spaces in Euskera, or rather, that is why before afternoon you have to take advantage of all the potentialities offered by artificial intelligence. I have tried to argue that the quality of the decision should be influenced and not the decision, since the contents in Basque can be read in Spanish or in French. And there will be more and more automatic translators.
I believe that digital, intelligent and multilingual communication projects should be developed, focused on Euskera, from the media that work exclusively in Euskera, in order, as I said, to increase the visibility and accessibility of the contents in Euskera in the sea of the erda population, and bring interesting contents to the Basque language. Each communication medium must imagine the strategies required by its scope and incorporate the technologies, inventing them some times and others correcting their direction, but not remaining in that attempt.
References.
Agerri, R., Saint Vincent, I. Campos, J.A. Barrena, A. Saralegi, X, Soroa, A. and Agirre, E (2020): Give your Text Representation Models some Love: the Case for Basque. In Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020). pp. 47814788.
Aldabe, I, Aztiria, J., Beltrán, F. Bras, M., C/ Ceberio, Cortes, I. Coyos D.O. Dazeas B. Sher, L. Labaka, G. Leturia, I., Sarasola, K. Séguier A. and Sibille J. (2019): LINGUATEC: Language resources for language development in the digitization of the languages of the Pyrenees in Natural Language Processing (SEPLN), ISSN 1989-7553.
Apodaka, E (2021): Irreversible. New. 2 May 2021.
Arana Arrieta, E. Amézaga Etxebarria, A. Egia Gutierrez, M. Goirizelaia Altuna, M., Laka Arrizubieta, N., Madariaga Ituarte, I. Miguélez Juan, B. Narbaiza Amillategi, B. & Zorita Aguirre, I. (2021): The virus attacked audiovisual consumption among young people. In Basque Media Yearbook 2021 (Vol. 1, pp. 105–120). Hekimen.
Artetxe, M. (2020: Automatic translation not supervised. Doctoral thesis. Faculty of Informatics, UPV/EHU.
Leturia, I. (2014): The Web as a Corpus of Basque. Doctoral thesis. Faculty of Informatics, UPV/EHU. Donostia-San Sebastián
Leturia, I (2021): Language and Basque technologies. Digital magazine sarean .eus. 4 February 2021.
Mimenza, L (2017): The Basque media in the giant Facebook network. Hekimen. Basque Media Yearbook.
Rojas, J (2020): Traduttore, traditor. Digital magazine sarean .eus. 12 December 2020. 29
Saralegi, X (2017): CLIR Techniques for minority languages. Doctoral thesis. 2017.
Saralegi, X (2021: Treatment of termination bias in machine translation. Presentation at Elhuyar Eguna. Unpublished.
Vaswani, A. Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N, Kaiser, L. & Polosukhin, I. (2017): Attention is all you need. Proc. of the 31st Conference on Neural Information Processing Systems (NIPS 2017).
1 https://en.wikipedia .org/wiki/AI-complete
2 This information appears in the Situation Report on Linguistic Technologies prepared in 2021 for the Vice Ministry of Linguistic Policy of the Basque Government.
3 Apertium is an automatic translation platform of ireic code based on profile rules: https://apertian.org
4 Matxin is an automatic translator created in 2007, the first automatic translator that translated from Spanish to Basque, based on rules and with open source. It was created by Elhuyar and the research group Ixaikerketa of the UPV/EHU http://matxin.elhuy.eus/
5 Now it is not available. The Basque Government has spent EUR 2.5 million and the ownership of the system (excluding dictionaries and lexicons) remains with the company. Most of the tenders (except initial) were awarded without public tender and amounted to around EUR 1.9 million. In my opinion, management is highly criticised, for the way in which awards are made, for the use of public investment, for not acquiring ownership of technology, for not promoting the open source system and for not having territorial research centres.
6 https://research .google/research -areas/natural-language-processing/
7 https://ai.facebook com/research/nlp/
8 The DeepText project has been financed under the call Associations of the Department of Economic Development, Sustainability and the Environment of the Basque Government in the field of fundamental research projects (KKK-2020/00088)
9 https://motel.gartner.com/bern-elliot/2021/02/18/ai-messenger-transl-services -are-re-the-localization-landscape/
10 am.eus
11 Time will tell whether there is room for everyone and whether the decision of the Basque Government has been the most appropriate in the event of a social initiative project, but I dare say: That the Basque Government will not be able to maintain the dynamism of some social organisations, that the integration of models will be increasingly cheaper (many organisations will easily have trained models with their data) and that the centralisation that EJIE is promoting will not make sense.
12 MODELA (KK-2016/00082), MODENA (KKK-2018/00087) and TANTE (KK-2020/00074) between Amezagañay, ISEA, HITZ Centre, Vicomtech and Elhuyar.