

Azken urteetan aldaketa handiak egon dira eta ikasketa automatikoko arkitektura neuronal berrien bidez aurrerapen izugarriak ezagutu ditugu lengoaia naturalaren prozesamenduan eta itzulpen automatikoan bereziki. Eraldaketa teknosozial berritu eta betean gauden honetan, euskarazko hedabideen eraldaketa digitalaren eta euskararen garapen osoaren auzia eskutik helduta datozkigu.
Adimen artifiziala eta lengoaia naturalaren prozesamendua: estrategia sinbolikotik ikasketa automatikora
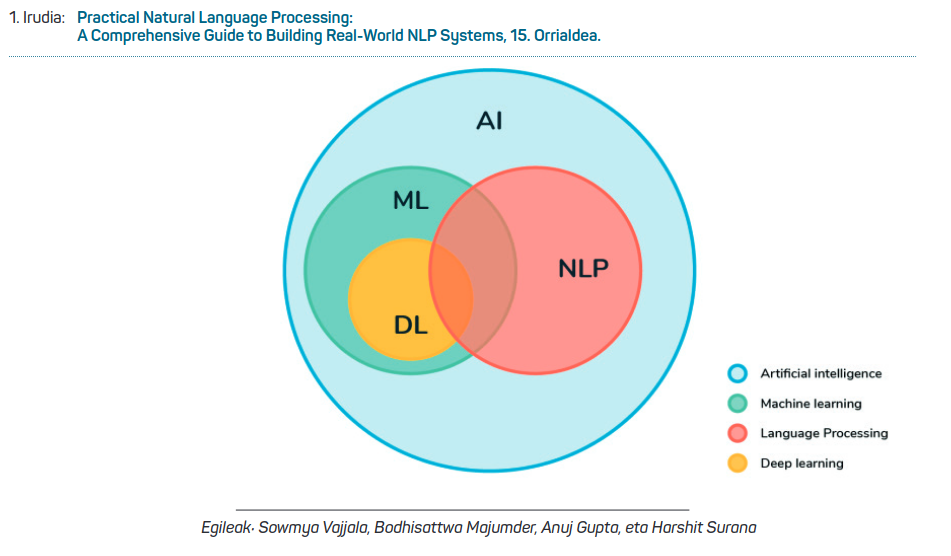
Adimen artifizialaren inguruko definizio zehatza ematea zaila eta ausarta den arren, esan daiteke konputazio-sistemen bidez pertsonen prozesu mentalak imitatu eta horietatik ikasteko gaitasunak sortzen dituen diziplina zientifiko-teknologikoa dela; hau da, adimen artifiziala makinek giza adimena imitatzeko duten gaitasuna da.
Honenbestez, adimen artifiziala makinek giza adimena imitatzeko duten gaitasuna bada, eta hizkuntzaren ulermena eta mintzamena giza adimenaren adierazpen nabarmenenak badira, Lengoaia Naturalaren Prozesamendua (LNP hemendik aurrera) adimen artifizialaren muin-muinean dagoen diziplina dela esan dezakegu. Esaterako, LNP AI-complete problem1 bezala ezagutua da adimen artifizialaren esparru zientifiko teknologikoan, hau da, algoritmo konplexuak eta sendoak eraikitzen diren adimen artifizialeko alorra dela hain zuzen ere.
UPV/EHUko HITZ Zentroak egindako txosten baten arabera2 Adimen Artifizialeko ikerketa-ekoizpenaren % 40 LNPrekin lotuta dago, eta honek eman diezaguke beraz, adimen artifizialak hizkuntzan azken urteotan izan duen bilakaeraren eta izango duen garapenaren neurria. Hizkuntzaren bidez pertsonen eta makinen arteko komunikazioa, baita pertsonen artekoa ere, errazteko tresna konputazionalak ikertzeaz arduratzen da LNP. Jarduera zientifiko-teknologiko giltzarria da beraz; eta are gehiago izango da etorkizunean.
Azken urteotan adimen artifizialak hizkuntzan aparteko aurrerapena izan du, batez ere sare neuronal sakonetan oinarritutako algoritmoen bidez, Deep Learning bezala ezagutua dena. Algoritmo hauen hobekuntzari esker zerbitzu ugari automatizatu dira, emaitza bikainak lortu dira ataza desberdinetan eta hizkuntza askotan; eta ongi dakigun bezala euskararekin ere emaitza bikainak lortu dira.
Orain arte adimen artifiziala eta zehazki lengoaia naturalaren prozesamenduan bi estrategia eta hurbilpen zientifiko nagusitu dira; alde batetik hurbilpen sinbolikoan oinarritutako paradigma; eta bestetik, 2010etik aurrera indarra hartu duen eta nagusi bihurtu den ikasketa automatikoan oinarritutako hurbilpena.
Hurbilpen sinbolikoaren arabera makinek ulertzeko moduko erregelen bidez deskribatu nahi izan da hizkuntza, hizkuntzak dituen maila eta ezaugarri guztien xehetasunak makinari irakatsiz: lexikoa, morfologia, morfosintaxia, sintaxia, semantika, pragmatika. Hurbilpen honetan berebiziko garrantzia izan du hizkuntzalaritza konputazionalak, hizkuntzalariak eta informatikariak elkarlanean hizkuntzaren deskribapena zorroztea eta sistematizatzea izan baita helburua; askotan, ordea, estaldura urriko sistemak eta teknologiak sortu dira. Hurbilpen sinbolikoa nagusi izan da LNPko ataza nagusietan orain gutxi arte eta baita itzulpen automatikoan ere. Itzulpen automatikoaren kasuan antzekotasun handiko eta egitura gramatikal antzeko hizkuntzen arteko ariketak egiteko emaitza onak lortu izan dira (Apertium3 erregeletan oinarritutako kode libreko sistema automatikoa dugu bide horren erakusgarri). Aitzitik, kode librean oinarritutako Matxin itzultzaileak4 (Elhuyarrek eta EHU/UPVko IXA Taldeak garatu zutena) edo Eusko Jaurlaritzarentzat Lucy Software enpresak garatutako sistemak5 oso urruti zeuden Apertium bezalako sistemen emaitzetatik. Hau da: gaztelania eta katalana edo galegoaren arteko itzultzaile automatikoek ongi funtzionatzen zuten, baina gaztelania eta euskararen artekoek ez.
Ikasketa automatikoan eta zehazki ikasketa sakonean oinarritutako estrategia da orain nagusi. Ikasketa automatikoan adibideekin erakutsitakoa ikasten du makinak (Testu-corpus handiak eta elebidunak), eta gero beste antzeko kasuetan aplikatzen ditu. Ikasketa sakonean gainera, erakutsitakoa ez ezik, erakutsitako horretatik eratortzen dena ere ikas dezake makinak: portaera hori lortzeko ikasketa sakonak sare neuronaletan oinarritutako arkitekturak erabiltzen dituelarik.
Ikasketa automatikoaren eta zehazki ikasketa sakonaren tekniken bidez adibideetatik ikasten duten sistemen nagusitasuna etorri da, hizkuntza-teknologien kalitatea, heldutasuna eta irisgarritasuna izugarri handituz. Esan daiteke, orain arteko tresnak heldutasun-maila baxua zutela, oraingoak aldiz produkzio-prozesu askotan txertatzeko modukoak dira.
Urteetan egin den ikerketa eta trebatutako goi-mailako ikertzaileak ditugu orain, Interneten eztandak testu-masa eta datu-bilduma erraldoiak ekarri dizkigu (makinek ikasteko adibide asko dituzte hain zuzen ere), sare neuronalak entrenatzeko konputazio-ahalmen handia dago eta korporazio teknologiko handiak esfortzu ekonomiko eta humano erraldoia egiten ari dira itzulpen automatikoa bezalako atazetan geroz eta emaitza hobeak lortzeko. Erabateko aldaketa eta eztanda ekarri du honek guztiak, eta orain arte irudikatu ere ezin genituen aukerak ireki zaizkigu parez pare. Hurbilpen honek iraultza ekarri du euskarazko hizkuntza-teknologietara.
Azken hiru urteetan gainera, LNP barruan erabat disruptiboa den paradigma-aldaketa berri bat ari da garatzen: hizkuntza-eredu neuronal orokorrak (domeinu zabaletara bideratuak) entrenatzen dira, gero, entrenamendu txiki batzuen bidez, gai garelarik beste domeinu bateko edo hizkuntza bateko atazetan bikain funtzionatzeko.
Korporazio teknologiko erraldoiak (Google6, Facebook7, Amazon, etab.) ikaskuntza sakoneko eta transferentzia bidezko ikaskuntzako (transfer learning) teknikak erabiltzen ari da dira LNP aplikazioak garatzeko. Adibide adierazgarri bat jartzearren, Googlek oraintsu aldatu du bilatzailearen oinarrizko algoritmoa aurrez entrenatutako hizkuntza-eredu neuronaletan oinarritutako algoritmo batekin.
Paradigma aldaketa honek aukera handiak ekartzen dizkio euskararen garapenari eta baliabide urriko hizkuntzei, izan ere, transfer learning teknikei esker baliabideetan (adibideetan, testuetan, datuetan) aberatsak diren hizkuntzen eta baliabideetan eskas diren hizkuntzen arteko ezagutza-transferentzia egin daiteke. Horri esker, baliabideetan aberatsak diren hizkuntzetako datuak erabiliz ikas dezakete sistemek baliabide gutxiago dituzten beste hizkuntza batzuetako aplikazioak garatzeko. Paradigma disruptibo honi modu egokian erantzuteko jarri genuen martxan 2020an DeepText proiektua Elhuyar, HITZ Zentroa eta Vicomtech ikerketa-zentroen artean. 8
Teknika horren bidez lortu ditugun emaitzak oso onak izan dira, eta aukera ematen dute entrenamendu-datu gutxi duten baliabide gutxiko hizkuntzetarako aplikazio bikainak eraikitzeko. (Agerri, San Vicente, Campos, Barrena, Saralegi eta Agirre, 2020)
Itzulpen automatikoaren hobekuntza: hurbilpen sinbolikotik ikasketa automatikora
Itzulpen automatikoaren merkatuak eta erabilerak hazkunde-tasa handia izango dutela aurreikusten dute Gartner etxeak bezalakoek egindako aurreikuspenek9 eta badu bere zentzua. Hazkunde horren eraldaketa-faktore nagusiak nazioarteko merkatu globalen hazkundea, digitalizazio-prozesuaren bizkortzea -telelana eta komunikazio digitala nabarmen areagotu- eta -COVID-19ak azeleratu duena.
Baina itzulpen automatiko neuronalaren (Neural Machine Translation) eztandak ere lagundu du igoera esponentzial horretan. Ikasketa automatikoa eta ikasketako sakoneko algoritmoek itzulpen automatikoaren kalitate-maila izugarri hobetu dute eta esan daiteke martxan zeuden prozesuak bizkortu dituela hainbat sektoretan disrupzio zantzuak agertuz, hala nola hedabideetan eta ikus-entzunezkoetan. Azken aurrerapenen atzean Transformer sistemetan (Vaswani et al. 2017) oinarritutako arkitektura neuronalak daude, izan ere, sare neuronaletan oinarritutako arkitektura hori bihurtu da itzulpen automatiko neuronaleko artearen egoera berria eta teknologiaren kalitatean jauzi ikaragarria ekarri duena.
Itzulpen automatikoan eman den jauzi kualitatiboaren erakusgarri da adibidez Elhuyarren Elia.eus10 itzultzaile automatiko neuronala; aski zabaldua, hedatua eta komertzialki enpresa eta erakunde askotan erabiltzen dena. Esaterako, 2020tik 2021era Elia Elhuyarren itzultzaile automatikoak % 40 egin du gora erabiltzaileetan, bi milioi bisitatik gora izan ditu aurten eta 610 milioi hitz baino gehiago itzuli ditu sistemak. Gaztelaniatik euskarara itzultzeko erabili da gehien, baina Eliak sei hizkuntzaren arteko itzulpenak egiten ditu: euskara, gaztelania, frantsesa, ingelesa, katalana eta galegoa.
Ez da merkatuan dagoen itzultzaile automatiko neuronal bakarra, jakina denez. Vicomtech-ek ere badu bere itzultzailea eta motor hori erabiltzen du Eusko Jaurlaritzako Itzuli zerbitzuak. 11
Elhuyarren hainbat ikerketa-proiektu jarri ditugu martxan azken urteotan gure sistemen kalitatea eta egokitzapen maila ahalik eta handiena izan dadin. Batzuetan elkarlanean, funtsezko ikerketa proiektuetan,12 eta ikerketa aplikatuko proiektuetan aldiz, gure kabuz; gero eta itzultzaile automatiko hobeak izan ditzagun euskararentzat. Itzultzaile automatiko pertsonalizatuagoak, kostu gutxiagorekin ezarri ahal izango direnak eta alborapen sozialik gabeak izango ditugu, eta geroz eta hizkuntza-bikote gehiagotan.
Itzultzaile automatikoaren pertsonalizazioa
Itzulpen automatikoaren merkatuan gero eta beharrezkoagoa da itzulpen pertsonalizatuak egitea, edukien eta erabiltzaileen berariazko eskakizunei zehaztasun handiagoz erantzun ahal izateko. Nahiz eta doitasun-mailak izugarri hobetu diren, hobekuntza horiek askoz txikiagoak dira testuinguru espezifikoetan. Alde horretatik, itzulpen automatiko pertsonalizatuen motorrek onura ugari ekar ditzakete itzulpen automatiko generiko ororen aurrean.
Garrantzitsuena itzulpenaren zehaztasuna hobetzea da, eta horrek, aldi berean, itzulpenaren kostua murrizten du (inbertsio txikiagoa edizio-ostekoan eta giza berrikuspenean). Itzulpen automatiko pertsonalizatuaren beste abantaila nagusietako bat itzulpen-estiloa eta lehentasunezko terminologiaren erabilera kontrolatzeko aukera da.
Itzulpen automatiko pertsonalizatua sintaxiaren, terminologiaren edo estiloaren erabilera jakin batera egokitu daiteke. Itzulpenen doitasuna hobetzeaz gain, itzulpen-zerbitzu pertsonalizatu batek erraztasunak eman diezazkioke hedabide bati itzulpen-eredua bere azpiegituran txertatzeko edo eredua modu erdiautomatikoan eguneratzeko. Horrek autonomia handia ematen dio bezeroari sistemaren pertsonalizazioa modu inkrementalean hobetzeko.
Azken urteotan beraz honakoak dira martxan ditugun ikerlerro nagusiak itzultzaile automatiko neuronalak geroz eta hobeagoak izateko:
-
-
- Itzulpen automatikoko ereduetan terminologia pertsonalizatua erabiltzeko aukera, profil terminologiko berri bakoitzeko eredu berririk sortu beharrik gabe. Terminologiaren egokitzapena. Itzulpenetan terminologia aplikatzea aukerakoa eta dinamikoa izatea, hau da, bezeroak terminologia jakin bat itzulpenaren unean erabili ala ez aukeratu ahal izatea, eta erabiltzen dituen hiztegi terminologiko edo glosarioak guztiz dinamikoak eta eguneratzen errazak izatea.
- Ereduak norberaren domeinu, erregistro eta estilora egokitzea: Bezeroaren corpusak edo testuak aurreprozesatzeko aukera, hainbat iragazki automatikoren bidez. Eredua norberaren domeinu, erregistro eta estilora egokitzeko aukera, fine-tuning tekniken bidez. Ondoren editatzeko eta berriz entrenatzeko aukera, egokitze-prozesu dinamikoa eta inkrementala ahalbidetzeko.
-
Konputazio behar txikiagoa izango duten sistemak sortzea
On-premise13 ereduak sortu eta Dockers-en oinarritutako itzulpen automatikoko sistema eramangarriak erdiautomatikoki sortzea da asmoa. Itzulpen automatikoko sistema arinak instalatu ahal izango dira ordenagailuetan edo konputazio mugatuko zerbitzarietan instalatzeko aukera egongo da. Honek aukera handiak irekiko ditu, izan ere, kostu eta baliabide gutxiagorekin sare neuronalekin entrenatutako itzultzaile automatiko bikain eta pertsonalizatuak erakunde askoren eskura egongo dira, pribatutasun eta kontrol-eskaerak ere hobe kudeatuz.
Genero eta gizarte-alborapen oro saihestuko duten sistemak sortzea
Azaldu dugun bezala, arkitektura neuronalek adibideen gainean eta aurrez sortutako testu-corpusen gainean ikasten dute, hau da, itzulpenetan, testuetan eta datu linguistikoetan dauden datuetatik. Datu horietan alborapenak baldin badaude (eta badaude) itzultzaile automatiko neuronalak alborapen horiek erreproduzituko ditu eta biralitate handiagoa eman esponentzialki hazten baita beraien erabilera.
Honenbestez, euskaratik gaztelaniarako itzultzaile automatiko neuronalean genero-alborapena saihesteko eta zuzentzeko ikerketa hasita dugu dagoeneko, entrenamendu-corpusa orekatuz edo eredua corpus orekatu batekin orekatuz. (Saralegi, 2021).
Etorkizuneko ikerlerro berriak
Aipatu dugun bezala eredu neuronalaren etorrerak aurrerapen izugarria ekarri du itzulpen automatikoan. Hala ere, gaur egun dauden sistemek datu asko behar dituzte (gainbegiratze sakona) eta corpus paralelo gisa normalean milioika perpaus behar izaten dituzte. Baina harrigarriki, gizakiok ez dugu baldintza hori behar hizkuntza eskuratzeko eta itzulpenak egiteko.
Mikel Artetxeren (Artetxe, 2020) helburua datu paraleloen mendekotasun hori guztiz ezabatzea izan da, corpus elebakarra baino beharko ez duten gainbegiratu gabeko itzulpen automatiko sistemak eratzeko. Gainbegiratu gabeko itzulpenak bide ugari ireki ahal dizkie entrenamendurako datu gutxi dituzten hizkuntzei eta etorkizuneko ikerlerro garrantzitsu baten aurrean gaudela esan daiteke Mikel Artetxe bezalako ikertzaileei esker (Facebook AI ikerketa-taldean dago orain).
Gure asmoak beraz argiak dira: itzultzaile automatiko neuronal hobeak eraiki nahi ditugu euskara beste hainbat hizkuntzekin lotuz, alborapenik gabekoak, pertsonalizatuak eta konputazio-kostu txikiagoa izango dutenak, hau da, kalitate handiko itzultzaile automatiko neuronal pertsonalizatuak, bideragarriak eta etikoak.
Eleaniztasuna, eraldaketa digitala eta albisteen kontsumoa testuinguru azeleratu berrian: eszenatoki hurbilak.
Hedabideen kontsumoa sare sozialen eta mugikorren bidez dator geroz eta gehiago; hedabidearen webgunera sartu gabe kontsumitzen dugu geroz eta gehiago hedabide horren edukia. Tokiko hedabideak dira esaterako Facebook bidez bisita gehien dituzten hedabideak eta Goierriko Hitzari bisiten %66 Facebook bidez iristen zaizkio (Mimenza, 2017).
Beraz, Facebook-ek itzulpen automatikoaren zerbitzuaren bidez edukiak itzultzeko aukera eskaintzen duenez, geroz eta hobeagoa denez eta izango direnez (ez soilik Facebook), hedabideek nahita edo nahi gabe ere, euren edukia itzulita jasotzen dute erabiltzaileek. Ez dira gutxi euskarazko hedabideetara iristen ari diren deiak eta kexak hedabidearen edukiek gaztelaniazko akatsak dituztela iritzita. (Rojas, 2020).
Horrek esan nahi du dagoeneko hedabideen kontroletik kanpo dagoen eduki handia beste hainbat hizkuntzetan jasotzen ari direla euskarazko erabiltzaileak, bai Facebook, Twitter edo gure nabigatzaileetan txertatzen diren itzulpen automatikoko sistema gehigarri desberdinen bidez. Laster eta ohartu gabe, jatorriko testua zein hizkuntzatan dagoen jakin gabe, irakurri ahal izango ditugu albisteak eta edukiak eta uste baino lehenago izan daiteke (Rojas, 2020). Eta hizkuntza interfaze huts bihurtzeko eta produktu digital soil bihurtzeko eszenatokia ere iritsi daiteke (Apodaka, 2021).
Artikuluaren hasieran azaldu dugun bezala gainera, hipotesi erreala da pentsatzea gero eta itzulpen-sistema hobeak izango ditugula eskuragarri, baita espero ez ditugun hizkuntzen artean ere. Facebook, Twitter Inc. eta Alphabet bezalako korporazio teknologiko handiak erruz ari dira horretan lanean. Horri gehitu gazteen eta etorkizuneko erabiltzaileen kontsumo-ohituretan sare sozialek duten pisua are handiagoa dela (Arana, Amezaga, Egia et el 2021), beraz, joera indartzen joango da.
Aipatu dugu gero eta eduki digital gehiago dagoela, eta pandemian euskal hedabide digitalen gorakada egon den arren, erdal hedabideak gehiago hazi dira 14. Ez da gutxietsi behar egin den lana, baina joera batzuk bizkortuko dira eta gure euskarazko edukien proportzioa gutxitzen joango da bestelako bideak jorratzen hasten ez bagara. Eduki digitalen gorakadak, komunikazio digitalen erabilpen masiboak, sare sozialen erabilerak eta adimen artifizialaren hobekuntzak aldea handitu besterik ez dute egingo. Sortzen den eduki digital demasa gure hizkuntzara ekartzeko, itzulpen automatiko neuronalak berebiziko rola jokatu beharko du ezinbestean.
Era berean, Euskal Herrian kokatuta dauden eta gaztelanian ardazten diren hedabideak ere euskarazko edukien eskaintza handitzen joango direla ez da hipotesi estrategiko irreala. Naiz.eus-ek esaterako, gero eta eduki gehiago eskaintzen ditu euskaraz eta itzulpen automatikoa txertatzeko ikerketa-aplikatuko proiektuan murgilduta dago, eta gauza bera esan liteke Noticias Taldea edo Correo (Vocento) taldeko hedabideekin. El Pais egunkariak (Brasilera edo Kataluniara egokitutako edizioak ditu), El Periodico de Catalunyak, La Vanguardiak, BBCk edota La Voz de Galicia bezalako agerkariek editatutako itzulpen automatikoa darabilte aspaldidanik.
Tokiko albisteei berebiziko garrantzia ematen dieten erdal hedabideak euskaraz eskaintzen hasiko balira, euskarazko tokiko albisteen eta ekosistemaren hegemonia izan duten hedabideentzat lehiakide garrantzitsuak izango lirateke. Ikustekoa izango litzateke irakurleengan eta harpidetzengan izango lukeen eragina, baina erreferentzialtasuna ahultzeko arriskua legoke. Itzulpen automatiko neuronalaren kalitateak, hedabideen eduki-sistemetan txertatzeko erraztasunak eta Katalunia bezalako herrialdeetan eman diren joerak ikusita, hipotesi erreala da hau berandu baino lehen gertatuko dela eta euskarazko hedabideek oso kontuan hartu beharrekoa da. Gainera, erdal hedabideek albisteak euskaratzeko dirulaguntza garrantzitsuak dituzte eta laguntza emateko irizpideek itzulitako kopurua saritzen badute pizgarri ekonomiko garrantzitsua zena are erabakigarriagoa izan daiteke jauziaren tamainan eta hau emateko abiaduran.
Beraz, laburbilduz, kanpo-aldagaiek eragin dezaketen mehatxuen aurrean hainbat hipotesi estrategiko aurreikusten ditut:
- Korporazio teknologiko handien eta sare sozial nagusien bidez euskarazko edukiak erdal hizkuntzetan kalitate handiz eskaintzen hasiko direla.
- Erdal hedabideek itzulpen automatikoa erabiliko dute euren edukiak euskaraz eskaini eta euskarazko produktu gehiago eskaintzeko, batez ere tokiko albiste eta edukietan.
- Gazteen kontsumo-ohiturek eta konpetentzia linguistiko eleaniztunak euskarazko hedabideekiko atxikimendua galtzea ekar dezake.
- Informazio gehiena beste hizkuntzetan ekoizten da eta euskarara ubide estu bat besterik ez dator.
Testuinguru aldakor, bizkor eta konplexu honen aurrean aukera eta esparru berriak ere irekitzen zaizkigu. Itzulpen automatikoa eta eduki eleaniztunak sortzeko erraztasunak bide, aukera eta esparru berriak ireki ditzake dudarik gabe, esploratu bai (gogoratu Euskaldunon Egunkariaren ingelesezko bertsioa) baina baliabide faltarengatik orain arte ezinezkoak izan direnak.
Euskarazko edukiak gaztelaniaz, frantsesez edo ingelesez zabaltzeak erabiltzaileen, ikusleen eta irakurleen kopurua handitzea ekar lezake, eta baita euskarazko edukien ikusgarritasuna handitzea ere. Izan ere, euskal hiztunoi soilik zuzendutako hedabide bat edukiak hedadura handiko hizkuntzetan zabaltzen hasiko balitz, euskara ulertzen ez duten irakurleengana iritsi ahal izango ginateke, Google bilatzailearen rankingeko azken lekuetan leudekeen euskarazko edukiak azaleratuko lirateke eta euskara erabat menperatzen ez duten euskal herritarrek erosoago barneratu ahal izango lukete edukia.
Gainera, aukerak zabaltzen zaizkie hedabidearen edukiarekin produktu edo zerbitzu berezituak eskaintzeko, hala nola, marka desberdin batekin beste hizkuntza batean edukia zabalduz edo beste hizkuntzetan atari tematikoak eskainiz. Adibidez, euskal politikan zentratutako katalanezko atari bat sortuz edo Elhuyar Aldizkariaren eduki globalak ingelesez zabalduz eta sona handiko zientzia-dibulgazioko agerkari digitalekin lehiatuz.
Bestalde, baliabide urriko hizkuntzen arteko itzultzaile automatiko bikainak sortzeko gai garen unean edo beste hainbat hizkuntza handietara zabaltzeko gai garenean, baliabide urriko hizkuntza askok gure edukiak erabili ahal izango dituzte euren garapen-prozesuan aurrerapauso handiak emanez eta orain urrun dauden beste hainbat hizkuntzekin zubiak eraikiz.
Amaitzeko, gure edukiak zabaltzeko gai garen bezala, beste hainbat hizkuntzetatik ere edukiak ekartzeko gai izango gara eta beraz, hedabide katalan, espainiar edo ingelesekin akordioak egin ahal izango ditugu gure hedabideen eskaintza ugarituz eta aberastuz. Jakin badakigu ez dela nahikoa itzulpen hutsarekin, lokalizazio ariketa eta edukien bitartekaritza lana egitea eskatzen duela, baina aukera bikaina dugu gure baliabide eta kazetariekin helduko ez ginatekeen edukietara ere iristeko, euskaraz.
Oso lagungarria izango da, gainera, euskarazko hedabideek eskura izatea itzulpen automatikoan puntakoak diren ikerketa-zentroak edota Elhuyar bezalako agente teknologikoak Hekimen-en parte izatea.
Horrez gain, euskaraz sortutako hedabideetan, sustraituak izanik eta haien misioa eta egitekoa euskararen garapenarekin estuki lotuta eta banaezina izanik,, ardura handiz bizi da euskaraz gain beste hainbat hizkuntzatan eskaintza zabaltzeko aukera. Gogoetak eta hausnarketak ezinbestekoak diren arren, eraldaketa digitalak eta digitalizazioaren azkartasunak eskatzen duten erabakiak geroratzea ekar lezake horrek, eta erabaki horiek norberaren borondatez baino kanpo-faktoreen eraginez hartzea. Gehiegizko analisiak ez dezala paralisia ekarri; horregatik, egon daitezkeen kezkei edo beldurrei iradokizun zehatzak eta irtenbide posibleak proposatzera ausartu naiz.

Euskara hutsezko hedabideetatik euskaraz ardaztutako proiektu eleaniztunetara
Euskarazko espazio hegemonikoa mantenduz eta hedabideon funtsa sendo mantenduz, eduki eleaniztunak eskainiko dituzten komunikazio proiektu eleaniztun eta multimediatara igarotzea izan daiteke marraztu dezakegun bide-orri posible bat. Honekin ez dut esan nahi hizkuntza-eskaintza eleaniztun simetriko batera joan behar denik, baina euskara ardatz izanik eduki eleaniztunak eskainiko dituzten hedabideak bilakatzea egin beharreko apustu estrategiko bat dela uste dut.
Oreka birtuoso bat bilatuz: alde batetik, euskararen komunitateak eta ekosistema komunikatiboak behar dituen euskarazko espazioen indartzeari eta hedatzeari erantzunez, eta bestetik, gure gaitasun eta ahalmen teknologikoen bidez (Leturia, 2021), eraldaketa digitalaren, sare sozialen erabilera masiboaren eta ikus-entzunezkoen kontsumo nagusitasunaren aurrean erdal ekosistema horretan gure lekua eginez.
Hau da, eduki digitalen gorakada esponentzialaren aurrean baliatu ditzagun itzulpen automatikoa, azpititulazio-sistema automatikoak eta hizketaren sintesi pertsonalizatuak (eta beraien arteko konbinazioak) euskararen hodia handitu eta eduki komunikatibo gehiago euskarara ekartzeko; eta bestetik, erabili ditzagun lengoaia naturalaren prozesamenduaren aurrerapenak eta aipatu ditudan teknologiak euskarazko hedabideon eskaintzak eduki digitalen itsaso horretan presentzia handiagoa izateko. Nire ustez, euskarazko edukiak beste hainbat hizkuntzetan eskaintzea ez da aukera bat, izan ere, plataforma teknologiko eta sare sozial erabilienak dagoeneko egiten ari dira; beraz, estrategia baten menpe, baina egin beharra dago, korporazio teknologiko erraldoiak dagoeneko zerbitzu hori eskaintzen ari direlako.
Ez zait iruditzen, beraz, hautuaz hitz egiteko unea denik; hautuaren nolakotasuna eta aurrera nola eramango dugun zehazteko abagunea da.
Lan-hipotesia (I): Hedabidearen eduki osoa hainbat hizkuntzetan eskaintzea itzulpen automatikoaren bidez.
Bide hau Elhuyarren Zientzia.eus atariak abiatu du eta ondoko orrialdeetan daukazue hautu honen inguruko gogoeta eta orain arte eman duenaren lehen ebaluazioa. Hedabide edo agerkariaren eduki guztiak automatikoki itzultzea da proposatzen den aukera bat, itzulpen automatikoak kalitate egokia ematen badu behintzat eta hedabide bakoitzak helburutzat jotzen dituen irakurle objektiboen araberakoa. Zientzia.eus une honetan euskaraz gain beste 5 hizkuntzetan ere irakur daiteke osorik (gaztelaniaz, frantsesez, katalanez, galegoz eta ingelesez) eta Eroski Fundazioaren Consumer aldizkariak bere eduki oro automatikoki euskarara itzultzeko hautua ere egin du, alderantziko bidea hain zuzen.
Bide honekin nire hipotesia da bisitari-kopuruak handituko direla, hedabidearen edukiak bilatzaileetan eskuragarriagoak izango direla eta euskarazko edukien ikusgarritasuna handituko dela. Ondoren, hedabide bakoitzak eskura dituen baliabide eta estrategien arabera erabaki dezake eduki hori zuzendu, partzialki gainbegiratu edo bere horretan utzi. Ekinbide berri honek ekar dezake Euskal Herritik kanpoko bisitari kopurua handitzea, euskara menderatzen ez duten erabiltzaileak gerturatzea eta Interneten euskarazko hedabideen ikusgarritasuna emendatzea.
Orain gutxi egin dio Berriak elkarrizketa Itziar Ituñori eta ingelesera itzuli du irandar batek. Gerta zitekeen Berriak elkarrizketa itzuli eta webgunean jartzea, eta ikusirik Itziar Ituñok duen sona bisita asko ekarriko lizkioke eta euskararen ikusgarritasuna handituko litzateke.
Kezka-iturri bezala aipatu izan da beste hizkuntzetara itzuliz gero bilatzaileetan gaztelaniazko edo ingelesezko albisteak agertuko liratekeela euskararen edukiaren aurretik; aitzitik, ez zait argudio oso sendoa iruditzen. Batetik, gaztelaniaz edo ingelesez bilatzen duenak sekula ez duelako euskarazko edukirik aurkituko bilatzaileetan; bestetik, beste hizkuntza batean aurkituta ere berri ona litzatekeelako bestela ez lukeelako eduki hori inoiz topatuko; eta azkenik, webgunearen konfigurazioa edo mugikorra euskaraz konfiguratuta edukitik webgunera salto egitean euskarazko eduki baten zuzenean sartzea behartu litekeelako.
Honenbestez, aukera honekin euskarazko edukien nagusitasuna mantendu dadin badaude bi gako garrantzitsu; batetik, erabiltzaileek nabigatzailea eta mugikorrak euskaraz konfiguratuta izatea eta bestetik; hedabideen webguneak egoki konfiguratzea gaztelaniaz indexatutako eduki batetik datorrena euskarazko edukira joan dadin (lehen aukera euskarazkoa izatea nahi badugu behintzat).
Beraz posible da teknikoki euskara ardatz izango duen hedabide eleaniztun bat martxan jartzea, eleaniztasunak dituen potentzialitateak eta euskararen hegemoniaren arteko oreka mantenduz.
Lan-hipotesia (II): Hedabidearen eduki osoa hainbat hizkuntzetan modu asimetrikoan eskaintzea itzulpen automatikoaren bidez.
Aurreko argipenak emanda ere hedabide batek erabaki dezake funtzionalki ere euskarazko eskaintzari balio erantsi handiagoa ematea. Ideia litzateke euskarazko edukiak beste hizkuntzetan ere ematea, baina funtzionalki euskarari lehentasun eta esparru hegemoniko handiagoa emanez. Laburpen automatikoaren euskarazko albisteak gaztelaniaz ere ematea, baina laburpena eskainiz eta ez erreportaje osoa. Euskarazko edukia aberatsagoa izatea (Hiz-gakoen erauzketarekin, bisualizazio-aukerekin, eduki gehigarri eta aberatsekin…)
Lan-hipotesia (III): Hedabideak produktu edo eskaintza komunikatibo bereiziak eta egokituak eskaintzea beste hainbat hizkuntzatan.
Hala nola, Berriak euskal politikarekin lotutako albisteekin atari espezializatu bat egin dezake katalanez eta ingelesez, edo Elhuyarrek Zientzia aldizkaria ingelesez argitaratu sarean. Marka propioaren barnean (BBCk edo El Pais egunkariak egiten duten bezala) edo marka bereizi baten pean egin liteke marketin-estrategiaren araberakoa izanik (Erdal hedabideek egiten dutena euskararekin: Gaur8, Ortzadar, Zabalik…).
Estrategia honek aukera eman dezake hedabide tronkala den horretatik bereizteko eta negozio-lerro beregaina bezala funtzionatzeko enborrari kalterik egin gabe, euskararen espazio hegemonikoari dagokionez, baina adar sendo bat ateratzen bada enborrak baliatu ahal izango du bere indarra sarrera gehiagorekin, muskulu gehiagorekin eta posizionamendu komertzial hobearekin.
Lan-hipotesia (IV): Euskarazko ikus-entzunezkoen azpidazketa eta bikoizketa masiboa.
Euskaraz ekoizten den ikus-entzunezko oro beste hizkuntzetara azpidaztea erabaki garrantzitsua izan daitekeela uste dut, batez ere euskarazko edukien ikusgarritasuna eta irisgarritasuna handitzeko. Hau da, transkripzio-teknologia eta itzulpen automatikoa bata bestearen jarraian erabili edo azpitituluak dauden kasuetan itzultzailea eta hizketaren sintesia ere erantsi bikoizketa automatikoa sortzeko.
Honenbestez, euskaraz ekoitzitako ekoizpenak euskarari lehentasuna emanez beste hainbat hizkuntzetan ere barneratu ahal izango lirateke iritsi nahi dugun komunitate edo herrialdearen arabera. Eta alderantzizko bidea ere bai noski: erakargarriak eta interesgarriak diren ikus-entzunezko pieza periodistikoak euskaraz azpidaztea. Horri, gainera, hizketaren sintesi pertsonalizatua jarriko bagenio (jatorrizko hizlaria imitatuz edo guk geuk sortutako ahotsen bidez) produktu komunikatibo asko ekarri ditzakegu euskarara gure eskaintza mediatikoa zabalduz, hedatuz eta aberastuz.
Lan-hipotesia (V): Elkarlanean proiektu komunikatibo berriak sortu nazioarteko sareekin.
Euskarazko edukiak baliatuta eta beste hainbat hizkuntzatan jarrita, eduki horiei beste ibilbide bat eman diezaiekegu, batez ere baliabide urriko hizkuntzentzat. Euskarazko eduki unibertsalak direnak balia ditzakete haien hizkuntza-komunitatearen berreskurapenean esparru komunikatibo beregaina eraikitzen laguntzeko. Pentsatzen ari naiz okzitanieran, galeseran, bretoieran eta Europako baliabide urriko hizkuntzetan; lehen urrats batean behintzat.
Laburbilduz
Azken urteetan aldaketa handiak egon dira eta ikasketa automatikoko arkitektura neuronal berrien bidez aurrerapen izugarriak ezagutu ditugu lengoaia naturalaren prozesamenduan eta itzulpen automatikoan bereziki. Hizkuntza-eredu neuronal berrien paradigmak ere are hobetu ditu emaitzak, kostu txikiagoarekin domeinu jakinetara eta hizkuntza desberdinen artean kalitate handiko erremintak eta aplikazioak sortzeko gai baikara.
Eraldaketa teknosozial berritu eta betean gauden honetan (kontsumo-ohituren aldaketa, eduki digitalen nagusitzea, pandemiak ekarri duen digitalizazio-prozesuaren bizkortzea) euskarazko hedabideen eraldaketa digitalaren eta euskararen garapen osoaren auzia modu bateratuan datorkigu. Alabaina, estrategia beregainak eta erabakiak hartzea dagokigu, bestela gure ordez korporazio teknologikoek diseinatutako algoritmoek hartuko baitituzte erabakiak.
Lan-hipotesi batzuk proposatu ditut eta izan daitezke beste batzuk ere, baina euskarazko hedabideen eraldaketa sustatzeko politika publikoek beste bultzada bat behar dute. Euskarazko hedabideon egitekoa euskarazko espazio hegemonikoak sortzea dela aintzat hartuta, edo hobe esanda, horregatik, adimen artifizialak eskaintzen dituen potentzialitate guztiak baliatu beharrean daude berandu baino lehen. Saiatu naiz argudiatzen erabakiaren nolakotasunean jarri behar dela indarra eta ez ordea erabakian, izan ere, euskarazko edukiak gaztelaniaz edo frantsesez irakur daitezke dagoeneko. Eta gero eta itzultzaile automatiko hobeak egongo dira.
Euskara hutsean funtzionatzen duten hedabideak izatetik euskaran ardaztutako proiektu komunikatibo digital, adimentsu eta eleaniztunak garatu beharko liratekeela uste dut, esan dudan bezala, erdaren itsasoan euskarazko edukien ikusgarritasuna eta irisgarritasuna handiagoa izateko; eta euskarara erdaretatik eduki interesgarriak ekartzeko. Hedabide bakoitzak bere esparruak eskatzen dituen estrategiak irudikatu eta teknologiak txertatu beharko ditu, batzuetan asmatuz eta beste batzuetan bere norabidea zuzenduz, baina saiatze horretan ezin geldituz.
Erreferentziak.
Agerri, R., San Vicente, I., Campos, J.A., Barrena, A., Saralegi, X., Soroa, A. and Agirre, E (2020): Give your Text Representation Models some Love: the Case for Basque . In Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020). pp. 47814788.
Aldabe, I, Aztiria, J., Beltrán, F., Bras, M., Ceberio K., Cortes, I., Coyos J.D., Dazeas B., Esher, L., Labaka, G., Leturia, I., Sarasola, K., Séguier A. and Sibille J.(2019): LINGUATEC: Desarrollo de recursos lingüı́sticos para avanzar en la digitalización de las lenguas de los Pirineos In Procesamiento del Lenguaje Natural (SEPLN), ISSN 1989-7553.
Apodaka, E (2021): Itzulezina. Berria. 2021eko maiatzaren 2an.
Arana Arrieta, E., Amezaga Etxebarria, A., Egia Gutierrez, M., Goirizelaia Altuna, M., Laka Arrizubieta, N., Madariaga Ituarte, I., Miguelez Juan, B., Narbaiza Amillategi, B., & Zorita Aguirre, I. (2021): Gazteen artean ikus-entzunezko kontsumoa astindu zuen birusa. In Euskal hedabideen urtekaria 2021 (Vol. 1, pp. 105–120). Hekimen.
Artetxe, M. (2020: Itzulpen automatiko gainbegiratu gabea. Doktorego-tesia. Informatika Fakultatea, UPV/EHU.
Leturia, I. (2014): The Web as a Corpus of Basque. Dokorego-tesia. Informatika Fakultatea, UPV/EHU. Donostia
Leturia, I (2021): Hizkuntza teknologiak eta euskara. Sarean.eus agerkatri digitala. 2021eko otsailaren 4an.
Mimenza, L (2017): Euskarazko komunikabideak Facebook sare erraldoian. Hekimen. Euskal Hedabideen Urtekaria.
Rojas, J (2020): Traduttore, traditore. Sarean.eus agerkari digitala. 2020ko abenduaren 12an. 29an
Saralegi, X (2017): CLIR Teknikak baliabide urriko hizkuntzetarako. Doktore-tesia.. 2017.
Saralegi, X (2021: Genero-alborapenaren tratamendua itzulpen automatikoan. Elhuyar Egunean egindako aurkezpena. Argitaratu gabea.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. & Polosukhin, I. (2017): Attention is all you need. Proc. of the 31st Conference on Neural Information Processing Systems (NIPS 2017).
1 https://en.wikipedia.org/wiki/AI-complete
2 2021ean Eusko Jaurlaritzako Hizkuntza Politikara Sailburuordetzarentzat egindako Hizkuntza Teknologien inguruko egoeraren txostenean ageri da datu hori.
3 Apertium kode ireiko itzulpen automatikoko plataforma da hizkuntza-erregeletan oinarritutakoa: https://apertium.org
4 2007an sortu zen itzultzaile automatiko bat da Matxin, gaztelaniatik euskarara itzultzen zuen lehen itzultzaile automatikoa, erregeletan oinarritutakoa eta kode irekikoa. Elhuyarrek eta EHUko Ixaikerketa-taldeak sortu zuten: http://matxin.elhuyar.eus/
5 Orain ez dago atzigarri. Eusko Jaurlaritzak 2,5 miloi euro gastatu ditu eta sistemaren jabetza (Hiztegiena eta lexikoena kenduta) enpresarena izaten jarraitzen du. Lizitazio gehienak (hasierakoa izan ezik) lehiaketa publikorik gabe esleitu ziren eta 1,9 milioi euro inguru izan ziren. Oso kudeaketa kritikagarria nire ustez: esleipenak egiteko moduagatik, inbertsio publikoaren erabileragatik, teknologiaren jabetza ez eskuratzeagatik, kode irekiko sistema ez bultzatzeagatik eta lurralde ikerketa-zentroekin ez kontatzeagatik.
6 https://research.google/research-areas/natural-language-processing/
7 https://ai.facebook.com/research/NLP/
8 DeepText proiektua Eusko Jaurlaritzaren Ekonomiaren Garapen, Jasamgarritasun eta Ingurumen Sailaren Elkartek deialdiaren barruan finantzatu da funtsezko ikerketa-proiektuen atalean (KK-2020/00088
9 https://blogs.gartner.com/bern-elliot/2021/02/18/ai-enabled-translation-services-are-changing-the-localization-landscape/
10 elia.eus
11 Denborak esango du ea guztiontzat lekurik dagoen eta Eusko Jaurlaritzaren erabakia egokiena izan den gizarte-ekimeneko proiektuko bat bazegoenean, baina ausartzen naiz esatera: Eusko Jaurlaritzak ezin izango diola gizarte-erakunde batzuon dinamismoari eutsi, modeloen integrazioa geroz eta merkeagoa izango dela (Erakunde askok erraz eduki ahalko dituzte beraien datuekin entrenatutako modeloak) eta ez duela zentzurimizango EJIEk sustatzen ari den zentralizazioak.
12 MODELA (KK-2016/00082), MODENA (KK-2018/00087) eta TANDO (KK-2020/00074) Amezagañay, ISEA, HITZ zentroa, Vicomtech eta Elhuyarren artean.